

Hello Readers !!! Welcome back to another Interpretable Blog Series.
Today, we will discuss one of the most interesting research papers from the year 2025 titled 'Semi-Supervised Learning from Tabular Data with Autoencoders: When Does it Work?'. This paper is written by Sintija Stevanoska, Jurica Levatić, and Sašo Džeroski from Jožef Stefan Institute, Slovenia.
So as usual, let's begin by understanding things from the ground level.
1. Why Are We Talking About This?
Let’s start with a simple observation, in the real world, not all data comes with a name tag or label attached to it.
Imagine you’re working at a retail company that collects millions of customers records every single month, their age, income, purchase history, browsing behavior, feedback scores, and even time spent on the website.
Now, out of those millions of records, maybe only a few thousand actually mention whether the customer finally bought the product or not. Those few thousand are what we call labelled data, because they have clear answers.
But the rest? They’re like a huge sea of unlabelled data, full of patterns, relationships, and hidden stories that are still waiting to be discovered.
Collecting labelled data is often expensive and time-consuming. Think about tasks like marking medical images as “disease” or “no disease,” or labelling financial transactions as
“fraudulent” or “normal.” It takes expert effort and human judgment, which means cost.
That’s where Semi-Supervised Learning (SSL) steps in a middle path between complete supervision and complete freedom.
2.Why Autoencoders for SSL?
Okay readers, before diving deeper, let’s pause for a second and understand why Autoencoders are such a perfect match for Semi-Supervised Learning (SSL).
Imagine you’re trying to summarize a 300-page novel into a single paragraph, you don’t copy every line, right?
Instead, you pick the most important points that capture the essence of the story. That’s exactly what an Autoencoder does with data.
An Autoencoder is a special type of neural network that tries to understand the heart of your data.
It has two main components:
- Encoder: Think of this as a smart data compressor.
It takes your input — say, 10 columns of customer information and squeezes it into a smaller, more meaningful summary called a latent representation. This latent space is like the “core idea” of the data stripped of noise, but full of insight.
- Decoder: Now comes the creative artist.
It takes that compressed code and tries to recreate the original data as accurately as possible.
The better the Decoder performs, the more we can say the Encoder has truly understood what matters most .
3. The Core Problem
While SSL works well for images, tabular data is tricky. Tabular features are independent and lack spatial relationships, so augmentations like rotations or flips don’t apply. This paper explores how to adapt SSL for such data.
4. Introducing SSLAE - Semi-Supervised Learning Autoencoder
Alright readers, now that we understand why labelled and unlabelled data both matters, let’s meet the star of this research - SSLAE, which stands for Semi-Supervised Learning Autoencoder.
Think of SSLAE as a very disciplined student who’s learning from two teachers at once
one who gives answers (labelled data), and another who gives hints (unlabelled data). The student’s goal is to learn from both not just memorize the answers, but also understand the deeper patterns that connect everything.
To make this possible, SSLAE is trained using two objectives that work hand in hand:
1.Reconstruction Loss (Lu): This part is like practicing how to remember what you’ve seen.
It teaches the model to recreate the input data from its own understanding even if no labels are given.
So, it’s like looking at thousands of anonymous customer profiles and learning what “typical behavior” looks like.
2.Classification Loss (Ls): This is the classic supervised learning part. It helps the model correctly predict outcomes like deciding whether a transaction is fraud or not using the labelled data we do have.
But here comes the beautiful part, SSLAE doesn’t treat these as two separate lessons. Instead, it balances both through a single combined formula:
𝐿=(1−𝜆)×𝐿𝑠+𝜆×𝐿𝑢
Here, λ (lambda) acts like a volume knob - controlling how much the model listens to each teacher.
If λ is small, it focuses more on labelled data (supervised learning).
If λ is large, it pays more attention to unlabelled data (unsupervised learning).
By tuning this balance carefully, SSLAE becomes capable of learning both what the data says and what it implies, creating a model that’s intelligent, flexible, and data efficient.
In short, SSLAE is not just memorizing, it’s understanding.
5. Architecture Explained
SSLAE has three parts:
- Encoder: Creates compressed latent features.
- Decoder: Reconstructs data.
- MLP Classifier: Predicts labels using latent vectors.
This shared structure allows joint learning from labeled and unlabeled samples.
6. Experimental Setup
So readers, now that we know what SSLAE is and how it learns, let’s talk about how the researchers actually tested their idea in the real world.
When scientists build a new model, they can’t just check it on one small dataset and call it a success, that would be like judging a movie based on a single scene.
Instead, they need to see how the model behaves in different situations easy ones, tough ones, balanced ones, and messy ones.
To make sure SSLAE was truly reliable, the researchers put it through a massive test drive. They used 90 different benchmark tabular datasets collected from popular open repositories like OpenML, UCI Machine Learning Repository, and PMLB.
These datasets come from all kinds of domains finance, healthcare, marketing, biology, and more each with its own challenges.
But here’s the catch: in real life, we rarely have plenty of labelled data.
So, to mimic that real-world scenario, they didn’t give SSLAE all the answers right away. Instead, they trained the model with only a small portion of labelled samples sometimes as few as 50, and at most 500 labelled examples.
The rest of the data was kept unlabelled, allowing SSLAE to figure out patterns on its own.
Now, how did they check whether the model was doing a good job?
For that, they used a very smart evaluation metric called AUPRC short for Area Under the Precision-Recall Curve.
In simple words, AUPRC tells us how well the model identifies true positives (correct predictions) without being fooled by false alarms.
It’s especially useful when the data is imbalanced like when “fraud” cases are much fewer than “non-fraud” ones.
The higher the AUPRC, the more confident we can be that the model really understands the difference between the important and unimportant cases.
By testing SSLAE across 90 datasets and multiple label ratios, the researchers didn’t just evaluate performance they tested its patience, intelligence, and adaptability in every possible condition.
And as we’ll soon see, the results were quite surprising!
7. Comparison with Other Models
Baselines included VIME, TabNet, TabTransformer, and FT-Transformer.
SSLAE – Semi-Supervised Learning Auto-Encoders consistently outperformed others, especially with very limited labeled data.

8. When Does SSL Actually Help?
Meta-analysis revealed SSL benefits most when:
- Classes are imbalanced.
- Feature-label relationships are non-linear.
- Data is complex or noisy.
In short, SSLAE shines where data is messy and labeled examples are few!
9. Visualization Insight
Scientific Diagram Placeholder: Autoencoder architecture showing encoder, latent space, decoder, and classifier.
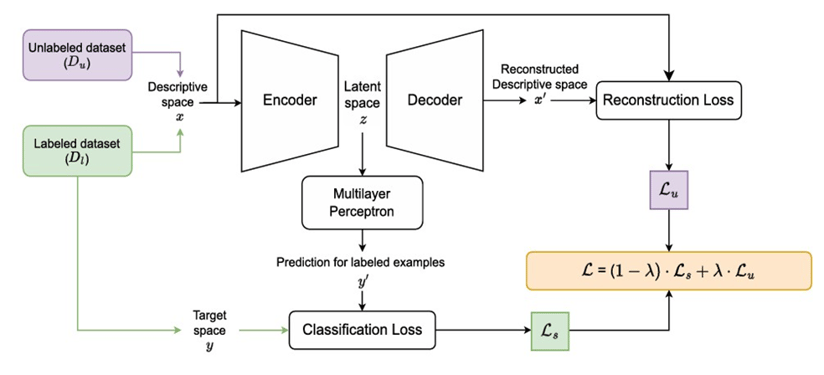
In a world of data, not every piece comes with a name tag. Some points speak loudly the labeled ones, telling us what they are and what they mean. Others remain silent the unlabeled, floating in the vast unknown, rich in patterns but without guidance.
To unite them, a bridge was built the Autoencoder. The Encoder listens closely, compressing what both the loud and the silent have to say into a secret language the latent space. It’s a quiet realm where meaning lives in compact form, free from noise.
The Decoder then takes this hidden knowledge and tries to retell the story, reconstructing the original world from its encoded essence. Each time it misses a detail, the Reconstruction Loss whispers what went wrong, teaching it to see better.
But not all knowledge is unsupervised. From the few that come labeled, another teacher the Classifier learns to predict their truths. It measures its missteps through Classification Loss, learning to speak the language of answers.
And so, the two lessons merge the wisdom of patterns and the clarity of labels bound by a gentle balance, λ, deciding how much of each voice to trust.
Together, they form harmony: a system that learns from the known and the unknown alike a learner that sees meaning even in silence.
10. Discussion and Insights
SSLAE is elegant in its design yet remarkably powerful in its performance. Unlike heavy transformer-based systems, it embraces simplicity while still achieving depth of understanding. What makes it special is how it weaves unlabeled data into the learning process not as an afterthought, but as an active contributor to model intelligence.
Through its composite loss function, SSLAE balances two worlds: the precision of labeled data and the abundance of unlabeled information. Every unlabeled example plays a role, gently refining the model’s internal representation and strengthening its ability to generalize. This design ensures that the model doesn’t just memorize patterns it learns structure, context, and continuity across both known and unknown data.
In doing so, SSLAE achieves what many complex architectures attempt with far greater computational cost, efficient learning through meaningful representation. It stands as proof that elegance and effectiveness can coexist beautifully in machine learning design.
11. Conclusion
- SSLAE: Semi- Supervised Learning Auto Encoding bridges the gap between supervised and unsupervised learning for tabular data.
- Combines reconstruction and classification elegantly.
- Performs best when labeled data is scarce.


