Hello Readers!!!
Welcome to 6th Blog of Interpretable Blog Series.
Here we are going to see how application of deep learning on Gage R&R is useful for detecting anomaly.
Okay! So as usual, let's start with complete 0. So very first question arises, what is this deep learning? What is R&R and what is this anomaly detection?
So, Deep Learning is a subset of Machine Learning which uses multiple layered neural network (which contains neurons) to learn complex structures, patterns from large and complex datasets. So, in short, we can say it is advanced extension of machine learning which use entire network for analyzing different patterns and extracting mathematically expensive features.
Secondly, Coming on Gage R&R, So, Gage R&R is a statistical technique which calculates reliability and precision of measurement systems. So it checks how “internally” the measurement system is failing to measure quantities.
And lastly let's talk about anomaly detection!!! So, readers, Anomaly detection is simply a method which detects “odd man out pattern” from dataset. That’s it!!! Just for an example,
Let's imagine very simple mathematical terms,
1, 5, 9, 13, 17, 22, 26.
So, if we see, numbers are following arithmetic sequence with common difference of “4” till 17. But after that instead of “21” there is 22.
So that number “21” is anomaly.
But it was observed that as current manufacturing industries are having very complex problems, so traditional methods like Gage R&R for measurements are getting failed to measure errors in manufacturing machines correctly. So, it was observed that with blend of Deep Learning and Gage R&R, systems become very intelligent to handle and detect errors.
Readers, this error here is basically an anomaly.
Overview of Gage R&R
The Automotive Industry Action Group (AIAG) defines Measurement System Analysis (MSA) as statistical properties of measurements obtained from a system which is working on very sound and stable conditions.
So, Gage R&R is the major concept from MSA.
To avoid further confusion readers, Gauge R&R and Gage R&R both are the same terms. There is only spelling difference.
Formal statistical definition of Gage R&R says that it is an approach used to identify how much of the observed variability in measurements can be attributed to the measurement system, as opposed to genuine differences in the parts being measured. So basically, it is a technique which separates human errors and instrument errors in two different groups!!!
For example:
Suppose we are having two different sticks one with 1m long and with 1.1m long. So, 0.1m is the actual difference between two sticks. As a measurement system, suppose we have to measure it from vernier calliper and calliper is having some fault like too tight ot too loose then we can get reading differently giving a foundational error.
Readers I believe the concept is clear till now.
Gage R&R is having two major components:
- Repeatability: In this aspect, operator measurement machine is same for one operator and the measurement experiment is carried out multiple times by different operators with their equipment to check if there is any variability.
- Reproducibility: In this aspect, Operator is different, but measurement system and other conditions are identical.
This aspect tells us about human error.
Below is the math's for Gage R&R

Methods Of Conducting a Gage R&R Study
- Crossed Gage R&R: This Approach requires each operator to measure every part multiple time, allowing for a comprehensive assessment of the variability of measurement system and then finally all the measurement differences will be studied for further analysis.
Must have balanced design

2. Nested Gage R&R: This is the approach when parts cannot be measured multiple times due to destructive nature of testing process.

3. Expanded Gage R&R: When MSA requires the evaluation of more than two factors (such as operator, Gage, Part, Laboratory, Location) This approach is used.

Gage R&R is having several statistical techniques to assess measurement system variability
Let's have a look on them in brief:
- Range Method: Provides quick estimate of variance measurement
- Average & Range Method: Provides a more comprehensive estimate, dividing variation into repeatability and reproducibility.
- ANOVA (Analysis of Variance): In this method total observed variation is divided into 4 sub-components:
i. Total Variation – It is a summarization of all variances from operators' error, Gage (instrument) error and processes
ii. Part-To-Part Variation – Variability due to differences in actual parts being measured.
iii. Equipment Variation – Variability due to precision limitations of gage (Instrument)
iv . Appraiser Variation – variability due to different operators measuring same part.
Now just for sake of information below I am giving a table for formulae of Gage R&R

TABLE: A
There are some guidelines for acceptance of measurement system for
Gage R&R which are foundationally made by Automotive Industry Action Group (AIAG) :
1. Total Gage R&R % Contribution:
– Measures: Proportion of total process variation due to the measurement system.
– AIAG Guidelines:
– <1%: Acceptable.
– 1–9%: May be acceptable (depends on application).
– >9%: Unacceptable (needs improvement).
2. Total Gage R&R % Study Variation (%Study Var):
– Measures: Measurement system variation relative to total observed variation.
– AIAG Guidelines:
– <10%: Acceptable.
– 10–30%: May be acceptable (depends on application).
– >30%: Unacceptable (needs improvement).
3. Total Gage R&R % Tolerance:
– Measures: Measurement system variation as a percentage of the tolerance range.
– Guidelines:
– <10%: Acceptable.
– 10–30%: May be acceptable (depends on application).
– >30%: Unacceptable (needs improvement).
4. Number of Distinct Categories (NDC):
– Measures: Ability of the measurement system to distinguish different parts or conditions.
– AIAG Guidelines:
– ≥5: Acceptable.
– <5: Insufficient resolution (may not differentiate parts effectively).
So,o Readers !!! we are almost done with the theoretical understanding of Gage R&R.
Now let's come on case study of Gage R&R
Case Study Using Gage R & R

TABLE: B
A total of 2500 fiction measurements were generated using GAN (Generative Adversarial Networks) from a sample measurement collected from the KNOX manufacturer. Dataset is having 3 components: ID, Operator, Parts.
Above is ran on two modes one with 5V & Another with 33V. Table above is showcasing a sample where 3 operators done 3 repetitions for 10 parts. So now, according to formulae given in TABLE: A, parameters are calculated. Their values are,
| Parameters | % we got after calculation |
| Total Gage R&R | 77.23% |
| Operator Part-To-Part Interactions | 38.78% |
| Reproducibility | 71.54% |
| Repeatability | 5.70% |
| No of Distinct Categories | 1 |
| Tolerance of Measurement System | 65.32% |
So readers,
It's your turn to identify whether the above system should be accepted as standard Gage R&R system According to Criterion specified OR not??
Answer Your Thoughts in Comments!!!
Now, let's come on most important part.
Thesis Statement
As we seen till now, we applied Gage R&R on univariate data.
Univariate here means operator noted only one measurement value for machine on which he was working i.e. machine was used to take only one parameter. But the thing is in current industry, there can be multiple parameters of measurements hence data becomes multivariate. In that scenario, Gage R&R can fail to give desired results up to specific thresholds.
Now to improve this, what should be done? Are there any advanced techniques which will tackle this traditional layer of Gage R&R ?
Let’s see in next chapter!!
Anomaly Detection And Auto Encoder
So As Discussed earlier, Anomaly is nothing but a deviation of specific data point OR group of points.
Why Autoencoders for Anomaly Detection?
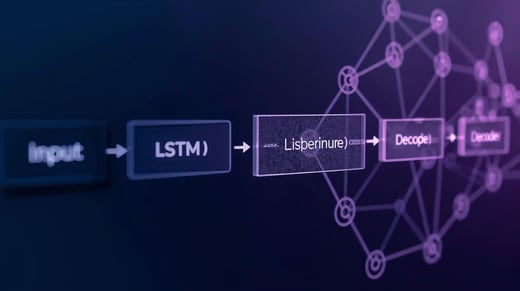
So, Readers, you might be wondering: what’s so special about autoencoders? Well, autoencoders are like magical data compressors. They take your big, messy dataset, squeeze it into a smaller, simpler version (called a latent space), and then try to rebuild the original data from that.
The cool part? If the rebuilt data looks way different from the original, that’s a clue you’ve got an anomaly!
Here’s the gist:
- Encoding: The autoencoder squashes your data into a compact form, keeping only the juicy, essential patterns.
- Decoding: It tries to rebuild the original data from that compact form.
- Reconstruction Error: The difference between the original and rebuilt data is your anomaly score. Big error? Probably an anomaly!
Think of it like summarizing a long book into a few sentences. If the summary misses key details, you know something’s off!
The Math Behind Autoencoders
Alright, let’s get a tiny bit math-y (don’t worry, I’ll keep it simple!). An autoencoder has two main parts:
- Encoder: Takes your input data (let’s call it ( x_i )) and transforms it into a smaller, latent space representation (( h_i )). Mathematically:
[ h_i = g(x_i) ] Here, ( g ) is a neural network with weights and biases doing the compression magic. - Decoder: Takes that latent representation (( h_i )) and tries to rebuild the original data (( \tilde{x}_i )). Like this:
[ \tilde{x}_i = f(h_i) = f(g(x_i)) ]
The goal? Make ( \tilde{x}_i ) as close as possible to ( x_i ). The difference between them (called Mean Squared Error, or MSE) is what we minimize during training:
[ \text{MSE} = ||x_i – \tilde{x}_i||^2 ]
Types of Autoencoders for Anomaly Detection
Readers, autoencoders come in all shapes and sizes, each with its own superpowers for catching anomalies. Here’s a quick rundown:
- Sparse Autoencoders (SAE): These are picky hey only let a few neurons activate, focusing on the most important features. Perfect for complex datasets!
- Denoising Autoencoders (DAE): They’re trained to clean up noisy data, making them robust for messy real-world scenarios.
- Variational Autoencoders (VAE): These treat the latent space like a probability distribution, great for dynamic data.
- Contractive Autoencoders (CAE): They’re tough against small changes in data, pulling out meaningful patterns even in noisy datasets.
- Convolutional Autoencoders (CAE): Built for images, these use convolutional layers to spot visual anomalies like a pro.
How Autoencoders Catch Anomalies
Here’s the game plan for using autoencoders to find those pesky outliers:
- Training Phase: Train the autoencoder only on normal data. It learns to rebuild “normal” patterns with super low error.
- Reconstruction Error: Feed in new data. The autoencoder tries to rebuild it, and you measure the error (difference between original and rebuilt).
- Thresholding: Set a threshold (like a line in the sand). If the error’s too big, boom that’s an anomaly!
Linking Back to Gage R&R
Now, how does this tie to Gage R&R? Remember, Gage R&R checks how reliable your measurement system is by separating human errors (reproducibility) and instrument errors (repeatability). Autoencoders can supercharge this by analyzing complex, multivariate data (multiple parameters at once) that Gage R&R alone might struggle with. By combining the two, you get a powerhouse for spotting measurement inconsistencies in manufacturing!
A Peek at ANOVA
Let’s sprinkle in a bit of ANOVA (Analysis of Variance) for fun! ANOVA is a statistical tool that breaks down data variability into two parts:
- Between-Group Variation: Differences due to things like operators, equipment, or parts (systematic stuff).
- Within-Group Variation: Random noise, like instrument inaccuracies or environmental quirks.
ANOVA helps us figure out if the differences we see are real or just random chance. It’s like a referee in Gage R&R, ensuring we know what’s causing measurement issues.
There are a few types of ANOVA:
- One-Way ANOVA: Looks at one factor (e.g., operator effect).
- Two-Way ANOVA: Checks two factors and their interactions.
- Repeated Measures ANOVA: Great when the same subjects are tested multiple times.
Case Study: Synthetic Data with GANs
Okay, Readers, let’s talk about the data we’re working with! This study uses fictional data generated by Generative Adversarial Networks (GANs) to mimic real-world measurements. The dataset has columns like ID, Operator, Parts, 5V, and 33V. For training the GAN, we dropped ID, Operator, and Parts, focusing on the 5V and 33V measurements.
Here’s how we prepped the data:
- Normalization: Scaled the data to fit between (-1, 1) using a Tanh function (perfect for the GAN’s generator).
- Data Handling: Created a custom dataset class (MyDataset) to turn data into tensors, then used a Data Loader to batch and shuffle it.
- Training: Ran the GAN for 2500 epochs. The discriminator learns to spot real vs. fake data, while the generator tries to trick it.
The result? High-quality synthetic data that looks super similar to the original, with just enough variation to keep things realistic. Check out the normal distribution graph (like Figure 8 in the original) to see how symmetric and clean the data is no wild outliers here!
Future Directions
Readers, we’re just scratching the surface! Autoencoders are already rocking anomaly detection, but there’s more to explore:
- Mixing with Stats: Combining ANOVA-based Gage R&R with autoencoders could create a super robust system for quality control.
- Real-Time Detection: Imagine autoencoders running on edge devices for instant anomaly detection in factories. Cool, right?
- Explainable AI: Making autoencoders more transparent with Explainable AI (XAI) techniques could help us understand their decisions better.
Your Turn, Readers!!!
So, what do you think? Are autoencoders the future of anomaly detection, or should we stick with traditional methods like Gage R&R? Drop your thoughts in the comments below! And tell me would you try building an autoencoder for your own data? Let’s chat!!!