

If you asked any AI practitioner a couple of years ago where the industry was heading, most would have pointed toward bigger and bigger models with billions of parameters and massive GPU farms behind them. The belief was simple. Bigger meant more intelligence. That belief is now being challenged in a very real way. In 2025 the most interesting breakthroughs are coming not from the giants but from the models that intentionally stay small.
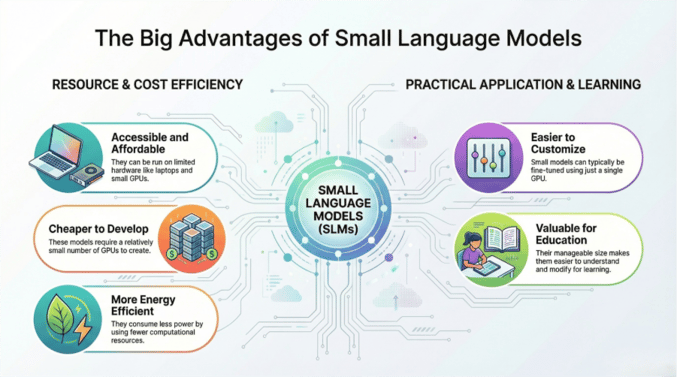
Small Language Models or SLMs have emerged as one of the most practical and cost effective ways to bring AI into real enterprise environments. They are fast, they run on surprisingly modest hardware, and they often perform extremely well on the kinds of structured tasks that organizations care about. They have shifted generative AI from something that only hyperscalers could afford to something that any business can deploy confidently.
Google CEO Sundar Pichai has repeatedly emphasized that the 'mobile shift' was just the beginning. In his 2025 address at the AI Action Summit, he noted that “intelligence is more available and accessible than ever before”, a vision realized through efficient models like Gemini Nano that bring intelligence directly to our smartphones.
Microsoft CEO Satya Nadella has articulated a clear view on how the global AI race will be won. In his recent remarks, he emphasized that “success will not be defined by who invents the most advanced technology, but by who adopts AI the fastest to create meaningful, real-world impact.” According to Nadella, the next wave of breakthroughs will come from organizations that move quickly to integrate AI into everyday workflows, products, and decision-making processes, rather than treating AI as a standalone innovation exercise. (Source: The Economic Times)
These statements reflect a truth that the industry is now embracing. Value does not always come from size. It comes from accessibility and the ability to solve real problems efficiently.
What Exactly are Small Language Models
Small Language Models are essentially compact versions of generative models designed to understand and process language but with far fewer parameters than the frontier models behind tools like GPT or Gemini. Instead of requiring clusters of high end GPUs they can run on a single GPU or even CPU only environments. Some SLMs are optimized to run directly on mobile and edge devices which means the model can live right where the data is generated.
This ability changes everything because it allows organizations to experiment, deploy and scale AI without committing to enormous budgets or sending sensitive data outside their secure environments.
Why Enterprises are Shifting from Large to Small Models
The first and most immediate reason is cost. Running a large model for a high volume workflow becomes incredibly expensive especially when millions of tokens are processed every day. SLMs reduce this cost dramatically. Enterprises are adopting cascade routing architectures to fundamentally reduce their AI inference expenses. This engineering strategy dictates that a smaller, faster model first attempts to process a request; only if the query is classified as complex is it 'cascaded' up to a larger, more powerful, and costlier model. Industry implementation studies confirm this efficiency. For example, analysis shows that well-designed cascade systems can achieve cost reductions exceeding 80% by limiting the use of premium models to a small fraction of total queries (Koombea)."
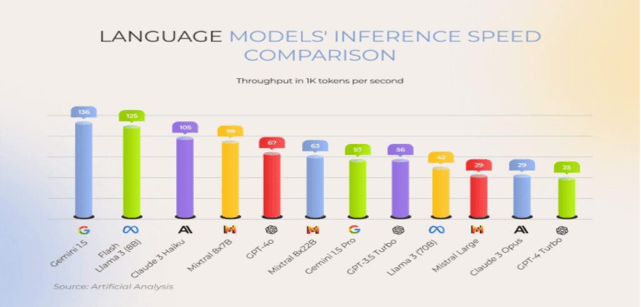
The second reason is latency. Smaller models process tokens faster simply because they involve fewer computations. Response times feel instantaneous which makes them ideal for customer support, internal copilots, conversational assistance and workflow automation. The perceived quality of an AI system often comes down to how quickly it responds and SLMs shine here.
The third reason is privacy and control. Many of the best SLMs like Llama 3.2, Phi-3, Phi-4-Mini, and Mistral 7B are available in open or self hosted formats. You can run them entirely inside your virtual private cloud or even on edge devices with no external API calls. For industries such as banking, insurance, manufacturing and healthcare this is a major differentiator.
There is also a philosophical shift happening. AI adoption is moving from “use a giant model for everything” to “use the right model for the right task.” SLMs are the practical proof of that idea.
Challenges Enterprises Face When Adopting Small Language Models
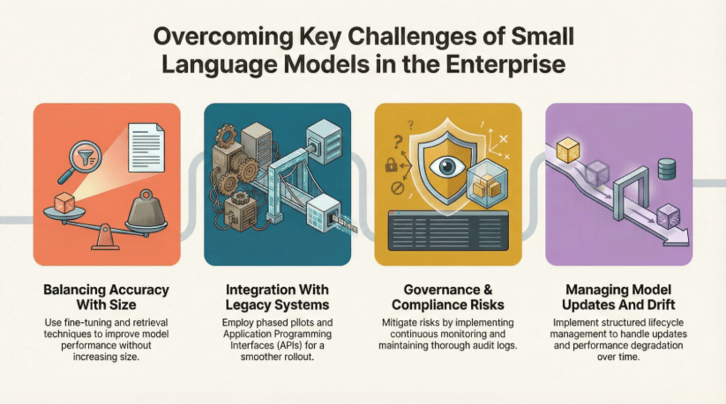
Even though Small Language Models deliver strong advantages in cost, speed and privacy, enterprises still encounter a few practical challenges as they scale them across workflows.
- One of the most common is balancing accuracy with model size. Modern SLMs perform impressively well, but some tasks still require deeper reasoning or richer context than a compact model can provide on its own. This is why many organizations rely on retrieval systems or hybrid routing strategies, where the SLM handles most requests and a larger model steps in for the truly complex cases.
- Integration with legacy systems is another hurdle. Enterprise environments are rarely clean or uniform. Introducing an SLM requires phased pilots, API abstractions and careful testing to ensure the model works smoothly with existing platforms without disrupting established processes.
- Governance and compliance also demand attention. Since SLMs often interact with sensitive financial, customer or operational data, organizations must maintain strong monitoring, audit trails and access controls. This ensures the model behaves consistently within regulatory and organizational boundaries.
- Lastly, teams need a structured way to manage updates and avoid model drift. SLMs evolve quickly, and without versioning discipline or evaluation pipelines, it becomes difficult to track improvements or maintain alignment as new variants are released.
These challenges are real, but they are manageable. With the right groundwork, enterprises typically find that SLMs offer the most practical balance of performance, control and long-term cost efficiency.
The Fast Evolving SLM Ecosystem
The last two years have seen remarkable progress in models under ten billion parameters.
Microsoft’s Phi series demonstrated that carefully curated training data can compensate for parameter count. Phi-3 and Phi-4-Mini models deliver surprisingly strong reasoning and coding performance at a tiny footprint. (Phi-3 Technical Report).
Meta’s Llama-3.2-1B and 3B models show deep language understanding despite their small size and were specifically engineered to run efficiently on laptops, mobile devices and edge systems. (Meta blog)
Mistral continues to push the boundary of compact high performing models. The Mistral-7B architecture is widely used in production because it is powerful yet simple to deploy. Tasks like transcription, summarization and context aware suggestions are now happening on device with no cloud dependency.
The message across the ecosystem is consistent. Small models are no longer “budget options.” They are strategic tools.
Where SLMs Truly Excel
Enterprises rarely need open ended conversations or philosophical reasoning. They need reliable performance on well defined tasks. This is where SLMs outperform expectations.
1. Document and knowledge workflowsSLMs perform exceptionally well for ticket summarization, email classification, invoice field extraction, complaint analysis, audit support, compliance checks and policy interpretation. When paired with Retrieval Augmented Generation (RAG) they deliver highly accurate, domain grounded answers.
2. Agentic automation
Many business processes follow predictable patterns. The model must read an instruction, identify an intent, fetch information and call internal APIs. SLMs are ideal as workflow controllers because the task relies more on structure and precision than deep generative creativity.
3. Internal and domain specific copilots
Embedding SLM powered copilots directly into CRM systems, ERP dashboards, HR portals or customer support consoles can significantly reduce manual effort. These copilots are fast, private and easily customizable.
4. Edge and on device applications
Use cases such as field inspections, equipment diagnostics, offline text processing, industrial monitoring and mobile assistance become feasible when the model runs directly where the user is. SLMs unlock this possibility.
The common thread across all these examples is efficiency. SLMs allow AI to integrate naturally into everyday workflows without overwhelming infrastructure budgets.
The Economics Behind SLM Success
When leaders evaluate AI investments they care about sustainability. They want to know whether the system can run at scale without spiralling costs. This is where SLMs fundamentally change the game.
- The per token cost is significantly lower.
- Inference infrastructure is lighter which reduces operational expenses such as power consumption, hardware costs and maintenance.
- Fine tuning small models is affordable which means organizations can create specialized domain versions of a model without multi crore training budgets.
Finally, a hybrid routing architecture where the SLM handles most requests and a large model handles rare complex cases gives the best balance of performance and cost.
This is why many enterprises describe SLMs as the “economics layer” of their AI strategy.
Implementing SLMs the Right Way
Successful deployments generally follow a few architectural patterns.
The first is a retrieval based architecture where the model focuses on language reasoning while enterprise knowledge comes from a vector database or document store. This keeps responses accurate and grounded.
The second pattern treats the SLM as a workflow engine. The model reads a request and produces structured JSON outputs that determine next steps. This approach makes automation predictable and easy to integrate with existing systems.
The third pattern is to embed several small copilots directly into the applications employees already use. This increases adoption since users do not need to learn a new interface.
These patterns allow SLMs to become part of daily operations rather than sitting in isolation as experimental tools.
The future of SLMs in enterprise environments
All signs point to a future where SLMs play a central role in enterprise AI. Training techniques like distillation, data curation and architectural optimizations are improving rapidly. New releases consistently demonstrate that smaller models can match or even surpass much larger models on real world tasks.
The next wave of innovation will be driven by the idea that intelligence should be “right sized” rather than oversized. Organizations will adopt models that fit their constraints, budgets and workflows while selectively using larger models only when absolutely necessary.
As Jensen Huang noted “The next era of AI will be defined by efficient computing.”
SLMs embody that philosophy perfectly.
- They make AI practical.
- They make AI affordable.
- They make AI private.
- And they make AI deployable in places where large models simply cannot go.
SLMs are not just a technical shift. They are a strategic shift.
They enable enterprises to scale AI confidently and sustainably and they represent the most meaningful step toward democratizing intelligence in real business environments.


