Refer this for authentic Research paper -
https://research.netflix.com/publication/is-cosine-similarity-of-embeddings-really-about-similarity
Glimpse of Essential Mathematical Background:
Basically, we all know about dot product OR Scalar Product in mathematics Right?
It is nothing but a A.B = |A||B|Cos(x) Where |A| and |B| are magnitudes of Vectors A and B
i.e. Suppose A = Xi + Yj then |A| = (X^2 +Y^2) ^(1/2)
The same goes for |B| And X is the Angle between Vectors A & B.
So now Mathematically, Cos(X) = (A.B)/|A||B| ….. Consider it Equation (1)
So, Now in Linear Algebra and hence in Data Science this Above Equation (1) is termed to be Cosine Similarity!!!.
So basically, Cosine Similarity is Nothing but a Cos of Angle Between Two Vectors. As we all know, the Range of Cosine Function is Between 0 and 1 [0,1], The range of Cosine Similarity is Also [0,1]. Right?
Cos0 = 1 And Cos90 = 0
It means if the angle between vectors is 0 they are 100% similar and if they have nothing in common
similarity is 0% I.e. Cos90.
Okay. So, moving forward, one basic question arises…and that is if there is Cosine Similarity then why not Sine Similarity????
So, we all know same as Dot Product/Scalar Product (A.B), there was Cross product/Vector Product (AXB), and it is mathematically given by, AXB = |A||B|Sin(X)n ……. Equation(2)
Where again |A| and |B| are magnitudes of vectors A and B. X is the angle between A and B And n is the unit vector So, AXB (Cross / Vector Product) is giving us A vector which is perpendicular to both A and B!!!
For better understanding look at a figure

AXB is a new vector with magnitude |AXB| which is perpendicular (90 Degrees Always) to plane of A and B.
Sin(X) = (AXB)/|A||B|……….(2)
It should be similar in correspondence to Equation (1).
So, AXB is not Scalar Quantity as A.B So, whatever we will get with using Equation(2) is A Vector in a specific direction with Similarity…
So, “Vector (with a direction)” being an unnecessary component while Checking Similarity which is a complete scalar quantity We don’t have Sine Similarity for Similarity Check!!!
Okay. I Hope all the Preliminary things are cleared. Let’s move forward to Netflix Research Paper Abstract
1. Abstract & Introduction
Let’s first have a short look on the embedding and
Normalization of vectors in Machine Learning
So, simply speaking, the Computers and Algorithms we use in machine learning are more compatible and faster with Numbers than Any Word/String. So, instead of directly checking the similarity between two words, If we preliminarily convert those words into real numbers and then apply similarity techniques like, let’s say Jaccard , Jaro or Cosine Similarity on them. It’s more accurate and has less Latency (Less time). And Secondly Normalization of vectors is nothing but dividing that Vector (A) by its respective Magnitude |A|
This technique makes every vector we made from string into unit length…
Which nullifies the pseudo effect of the difference we are getting due to different lengths of vectors.
Got it???
(Norm is the term for magnitude in Linear Algebra Language)
So moving forward, Researchers from Netflix found out that, Cosine Similarity shows arbitrary and vague results in many cases. And surprisingly works well in some cases when the Embedding / Vectors (that we made by using ML algorithms) of Strings are not even normalized!!! If normalization is major key to increase accuracy of similarity, then without doing normalization how Cosine similarity is giving better results compared to application of cosine similarity on normalized vectors.
How’s that possible??
Their findings are Cosine Similarity is not a problem. The real Problem Lies within the Declaration of Embedding to Strings!!!!
Let’s see how it goes with some Math!!!
2. Matrix Factorization Model
Let's understand what is this??? And then we will go on findings of Netflix on this by simple mathematical example…
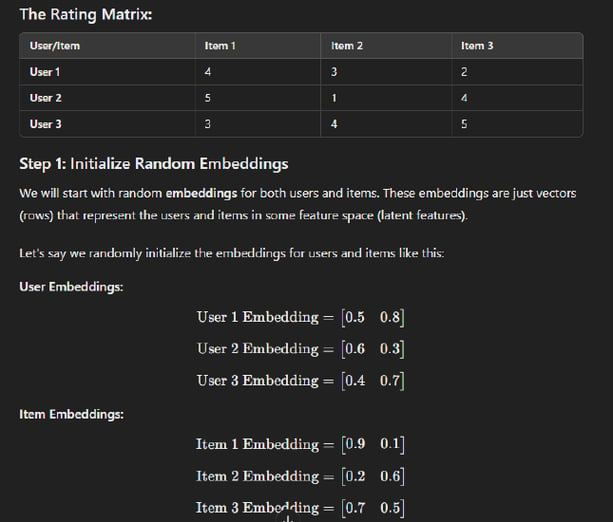
So, Suppose Netflix itself is having dataset where rows are users and columns are names of different web/series names. So now, Let that Dataset is Matrix X with n rows and p Columns. i.e. X (nxp).
Now mathematically to generate some numbers for those (nxp) entries we have to decompose the above
Matrix X in such a way that XATranspose(B) = X, Where A is matrix of order (Users X Features) …. (1)
And Transpose(B) is matrix of order (Feature X items) …s) …. from (2) and (X) is original Matrix. We can take any number of Features = K As we all know matrix multiplication is only possible for AXB when columns of A and rows of B are the same!!! Right!!! So, finally using (1) and (2) we will get X!!!
So the only question is which values should be there inside A and Transposed(B) so that after doing
Matrix Multiplication we will get approximately the same values of matrix X And those Values inside A and Transposed(B) are Embeddings !!!.
Now let's see what Netflix is claiming on above model by simple example…
Primary matrix is X as follows:

What we are doing on Matrix X By Using Matrix Factorization Model:

What we Got:

So…We can clearly say that those Embeddings are not Proper which are formed by Matrix Factorization Model As they are Not Matching Preliminary Values of Matrix X!!!!
After performing Matrix Multiplication XATranposed (B) = X.
We got,

These values are not at all close to Original Matrix (X)….
Here’s the Actual Problem Begins…
Mathematically, Expression XATransposed (B) failed to be the Decomposition of Matrix (X).
Its impact on Dot / Scalar Product and Cosine Similarity :

This Dot Product is indicating that User 1 will rate Movie1 as 0.68 but actual Rating is 5.

Here Cosine Similarity is checking the Similarity between Two Movies and it’s found to be 0.83..
It’s completely based on rating the same user given to different Movies.
As Matrix Factorization Model is Not giving Appropriate Numbers (Embeddings) Related to Preliminary Matrix (X) Its actually a loss of Data So, How can we Rely on above Numbers ???? Isn’t it?
Now let’s check the approach of Netflix for the training model on the above situation….
3. Training
Expression – Objective (1)
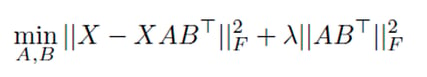
Is used for Model Training. That First Part ( || X – XATransposed(B) || )^2 ……(4) is again decomposing Matrix (X) into A and Transposed(B)
(by declaring the numbers that are actually Embeddings.) – Recall
However, it’s obvious that Minimum the quantity || X – XATransposed(B) ||, The model is a better fit…Isn’t it?? Now let’s Look at the second part. Its, (Lambda (A Transposed(B))) ^2. ……. (5)
This quantity is there only to add a Penalty to the Model we fitted in (4).
This part (5) Refers to the Regularization term in Machine Learning!!! Which in common sense reduces the overfitting and complexity of the model.
Expression – Objective (2)
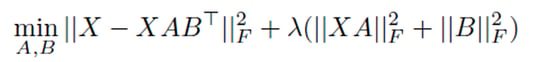
First part (|| X – XATransposed(B) ||) ^2 Is the same as explained above…
Even the Second part of the equation,
Lambda (|| XA||^2 + ||B||^2)
Is same as expression (5).
It’s nothing but a regularization term as previous example for reducing overfitting of model. But here, the only thin difference is Matrix(A) and Matrix(B) are kept small individually by keeping them separate mathematically!!! It’s the same thing as weight decay in Deep Learning… You got it???
Yes!!!!
It is mentioned that for Matrix Decomposition Rotation Invariance and Rescaling Invariance are mandatory. What is that? In Simple terms, we are forming Matrix(A) and Matrix(B) decomposed from Matrix (X). So these newly formed Matrices (A) and (B) contain embeddings.
Rotation refers to changing direction of data. Suppose, we have data values going in increasing order, If we multiply whole data by (-1) entire values will be decreasing. i.e. after multiplying by (-1) we got rotation of 180 Degrees!!! Right?
So, Suppose if those two Matrices (A) and (B) are carrying such a data which is neither increasing nor decreasing Rotation will have no impact on that !!! So , it will open up new and flexible solutions for getting embeddings and speeding up convergence process during training.
Lets take example for increasing Data – Matrix , Decreasing Data – Matrix & Stable Data Matrix (Rotation Invariant Matrix)
Increasing Data Matrix

Each element is smaller than its next, Diagonally, column-wise, or row-wise element. Decreasing Data Matrix

Each element is bigger than its next Diagonal, Row wise, and column-wise Element. Stable – Data (rotation Invariant Matrix)

There is no observed increase or decrease in the next diagonal , column-wise or row-wise element.
These above type of matrix is preferred for declaring embeddings as we rotate such matrix there is no issue with the direction of elements allowing us more flexibility and speeding up convergence process towards Correct Decomposed Matrix (A) and (B)
So X = XAtransposed(B).
Got it!!!
Okay now let’s move on to rescaling invariance.
Scaling basically means Multiplying all quantities by a specific scalar (say M). And Angle is independent of scaling. Let’s see one basic example. Suppose we have square ABCD of side 4 units. The angle between those two sides is 90 as it is square. Now if we multiply each side by 4 then a new square HDFC formed is of side 16 cm which is similar to a square ABCD by Angle-side-angle, Side-side-side similarities. And still angle between those sides is 90. Isn’t it?
This shows how an angle is immaterial in scaling.
As we know now, Cosine Similarity is checks an angle between vectors, Cosine Similarity is also immaterial of angle. So, while checking Cosine Similarity we need not worry about taking scalability of Matrix (A) and (B) !!!. I am pretty sure that Concepts of Rotation & Rescaling Invariance is cleared.
Now Let’s See What Diagonalization is.
The process is basically multiplying Matrix (A) by some Diagonal Matrix (D) and Matrix (B) by Inverse(D)
This Diagonal Matrix (D) makes Matrix(A) and Matrix(B) Rotation Invariant (As explained above).
Then we get New Matrices AD and B(D inverse). After that we have to divide Matrix AD by ||AD|| and B(D inverse) by ||B (D Inverse)||
|| X || – refer to magnitude of matrix X The first part, Getting AD and B( Inverse D) is Diagonalization
And Second Part, Division by magnitude is termed to be Normalization !!!
Normalization Converts every Vector say A in Unit length removing the Ambiguity of different lengths of vectors.
And convert all vectors on the same Ground easy to compute for the Application of Cosine Similarity!!!
I believe that the concept is crystal clear!!!
4. Impact of Diagonalization on First and Second Objectives
In the First Objective, the Diagonal Matrix (D) is chosen arbitrarily. If D is chosen such that its effect is too strong, it could lead to a situation where the cosine similarity between items is zero (i.e., items are only similar to themselves).
This is not desirable, as it would make the model behave in a way where items are not comparable in terms of similarity. AS, Its effect of D.
FIX FOR FIRST OBJECTIVE :
Choosing Such D, which is having similar structure as Matrix(A) and Matrix(B). Inheriting structure of (A) and (B) in D removes that noisy effect of Diagonal matrix (D) on Cosine Similarity. Now Impact of D on Second Objective is, Here, D is taken symmetric and fixed, meaning both user and item embedding are normalized in the same way. This leads to consistent and stable cosine similarity values between users and items, and between items themselves.
Since there is no arbitrariness in D, the results of the cosine similarity are more predictable and meaningful, which is desirable in practical applications.
That FIX D in Second Approach is taken by following formula :

Basic Example of Calculating D :



After all the discussion and examples we have seen we can clearly conclude that the second approach is better than first approach for Diagonalization and Normalization.
But as cosine similarity majorly depends on diagonalization hence on Matrix (D), Results can be Arbitrary and irrelevant!!!
5. Remedies by Netflix Researchers on the above Problems.
REMEDY – 1 – TRAINING DIRECTLY WITH COSINE SIMILARITY
Problem – Training Model with Dot Product i.e. Matrix Decomposition Algorithm shows irrelevant results.
Solution – In spite of using Dot Product (A.B) we can use Cosine Similarity for the training model. Which will improve accuracy. We will see the similar example but now by using cosine similarity for training



REMEDY – 2 – DIRECT APPLICATION OF COSINE SIMILARITY WITHOUT GENERATING EMBEDDINGS
Another remedy is to avoid the embedding space (which can lead to problems with cosine similarity) and instead work with the original data. You can project the data back into the original space (before embeddings were applied), where cosine similarity can be directly calculated on the original data.
Summary of above remedy is that avoid using Embeddings OR vectorization on data as primary treatment. If we are not having any option left then only jump on embeddings / Vectorization.
NOTE – THIS ABOVE METHOD IS APPLICABLE ONLY TO NUMERICAL DATA
REMEDY – 3 – NORMALIZING DATA BEFORE APPLICATION OF COSINE SIMILARITY
In many cases, cosine similarity is applied after the embeddings are learned, but this can lead to reduced similarity accuracy. To fix this, it is better to normalize the data before or during training. This is a very Basic Step but can impact accuracy a lot.
6. Experiment by Netflix!!!
Netflix Simulated Data of 20,000 Users and 1000 items. Where there are 5 clusters depending on genre of items. Each cluster is having 200 items. Then they declared popularity scores to each item in each cluster on the basis of its popularity. And obviously now, Any entry lets say A22 will tell us rate given by user 2 to item 2. Right????
I believe it’s clear !!!
So moving forward, Then embeddings are generated using Matrix Decomposition Algorithm we looked at start. Where Matrix (A) is Users & Matrix(B) is Items Then Cosine Similarity is applied to check similarities
between two items. it’s generic same as above!!!
We tested two Training & Rescaling Approaches :
1. Flexible Scaling-
This method allows the embeddings to be rescaled, which can lead to different similarity results depending on the scale.
Here It simply means Normalization is not done Before applying cosine similarity.
2. Fixed Scaling- (Priorly did Normalization)
This method enforces a fixed scale on the embeddings, which makes the cosine similarity results consistent and closer to the true item clusters. I am pretty sure that till this part readers including people from non-mathematical background are also clear about the problem behind application of Cosine similarity. Now lets jump on last part Conclusions!!!
7. Conclusions
Here are some conclusions in simple ways:
- Cosine Similarity Measures the Angle (X) between two vectors if value of Cosine similarity is 1 they
are similar If its 0 then they are different. Range of Cosine Similarity is [0,1]. - Matrix Decomposition Algorithm breaks one single large matrix X (dataset) into two small matrices A and B Such that XATransposed(B) = X. In A and B the Entries are Embeddings
- First and Second Objectives in above Blog Represents Regularization of model. First objective adds (||ATransposed(B)||)^2 to (||X – XATransposed(B)||)^2 And in Second Objective term (||A|| + ||Transposed(B)||)^2 is added individually to (||X – XATransposed(B)||)^2 These extra terms both in first and second objective is to add penalty to model (||X – XA*Transposed(B)||)^2 to avoid overfitting.
On similar note it restricts entry values of Matrix(A) and Matrix(B) to specific limits. - Simulated data (where actual similarities between two strings / numbers are known) can be used to
check effects of different embeddings on cosine similarity. This approach enables us to get Actual & Predicted Values. - In deep learning models (which are more complex), different layers apply different techniques, making it even harder to interpret cosine similarity. The embeddings might be scaled differently in each layer, leading to confusing results.